

Beginner’s Guide to Neural Networks, Artificial intelligence is transforming almost every major industry in our modern digital world. At the absolute center of this technological revolution lies a powerful mathematical framework called a neural network.
This advanced software structure allows computers to learn from massive amounts of data in a highly organic way. Understanding this concept is no longer reserved exclusively for elite computer scientists and academic researchers.
This comprehensive guide breaks down the complex inner workings of these fascinating digital minds into simple, accessible ideas. We will explore the basic structural components, the learning process, and real-world practical applications. These foundational concepts will help you navigate the rapidly evolving landscape of machine learning with absolute confidence. Let us embark on this exciting journey into the heart of modern artificial intelligence.
What is an Artificial Neural Network?
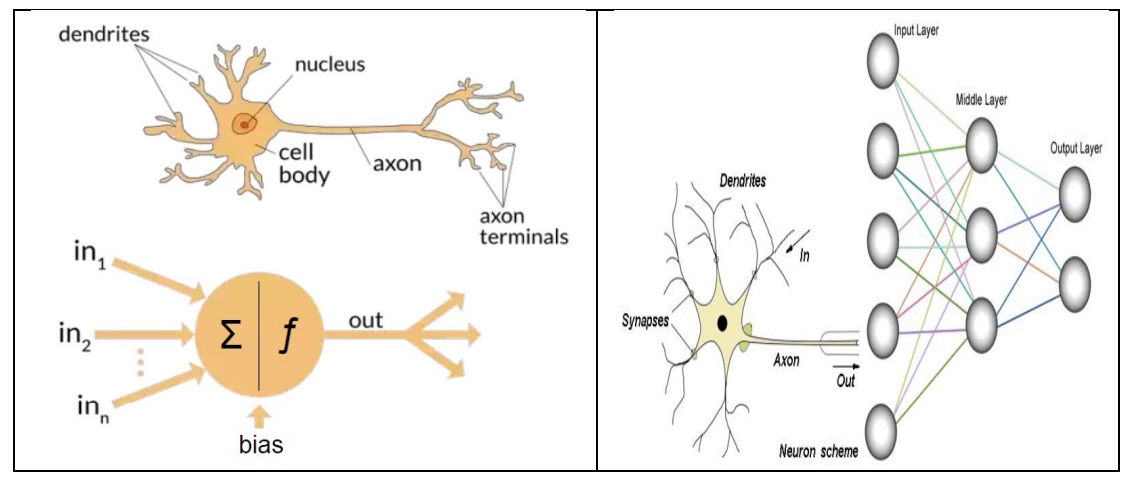
An artificial neural network is a sophisticated computational model inspired directly by the human biological brain. The human brain utilizes a massive interconnected web of billions of biological neurons to process sensory information. Similarly, computer scientists build digital networks using software equations to mimic these natural biological structures. These systems excel at identifying intricate visual or mathematical patterns that traditional software programming completely fails to grasp.
What makes this approach so fundamentally different from standard, old-fashioned computer software code? Traditional computer programs require explicit, step-by-step instructions to perform even the simplest daily computational tasks. In stark contrast, a neural network learns how to solve complex puzzles by analyzing thousands of historical examples. This unique capability allows the computer to adapt dynamically to completely fresh information without manual reprogramming.
Furthermore, these systems handle highly unstructured data like messy photos, raw audio, and human text effortlessly. Over time, the network refines its internal mathematical logic to boost its predictive accuracy significantly. This remarkable adaptability forms the absolute backbone of almost all cutting-edge artificial intelligence systems today. It transforms standard, rigid computers into fluid machines capable of generalized cognitive learning.

The Core Structure of a Network
To understand how a neural network operates, you must first visualize its basic structural physical layout. Think of a network as a highly organized factory containing multiple specialized processing lines. Data enters through one side, undergoes various transformations, and exits as a finalized prediction on the other side. This orderly progression relies entirely on three distinct layers working together in perfect computational harmony.
The Input Layer
The input layer serves as the primary gateway for all external data entering the system. Each individual neuron in this initial layer represents a specific piece of information from your dataset. For example, if you feed a digital photograph into the network, each pixel becomes an independent input value. This layer does not perform any complex mathematical calculations on the data itself. Instead, it simply passes the raw information down the line into the deeper processing zones.
The Hidden Layers
What’s interesting is where the real computational magic actually happens within this intricate digital architecture. The hidden layers sit quietly between the initial input layer and the final output layer. A basic network might feature only one hidden layer, while advanced deep learning systems utilize hundreds of them. These layers continuously extract abstract mathematical patterns and structural features from the incoming data streams.
As information passes through each successive hidden layer, the calculations become increasingly complex and sophisticated. The first hidden layer might detect simple geometric shapes like straight lines or sharp corners in an image. The next layer combines those lines to recognize recognizable facial features like eyes, noses, or ears. This step-by-step extraction process allows the system to comprehend highly intricate concepts automatically.
The Output Layer
The final destination for the processed information is the highly critical output layer. This concluding layer translates the deep mathematical calculations of the hidden layers back into a human-readable format. It delivers the final prediction, classification, or decision based on the patterns identified during processing. For instance, it might output a definitive answer stating whether a medical scan contains a dangerous tumor.
How the Digital Neuron Calculates Data
Every individual artificial neuron inside the network functions as a tiny, independent mathematical calculator. A neuron receives multiple digital signals from its neighbors simultaneously, processes them, and transmits a single output signal forward. This localized computation relies heavily on three core mathematical concepts known as inputs, weights, and biases. Mastering these three simple variables unlocks a complete understanding of how a network thinks internally.
Each incoming signal carries a specific weight value that dictates its overall importance to the neuron. Think of weights as a customizable volume dial that amplifies or dampens specific pieces of incoming information. If a particular input is highly relevant to the final goal, the network increases its specific weight value. Conversely, irrelevant or noisy data points receive incredibly low weights to minimize their impact on the system.
Furthermore, the neuron adds a unique numerical value called a bias to its total mathematical calculation. The bias allows the neuron to shift its final output up or down independently of the incoming signals. This flexibility ensures the network can make accurate predictions even when the input data is completely blank. Once the weighted inputs and biases are summed together, the neuron passes the result through an activation function.
The Role of Activation Functions
An activation function acts as a strict digital gatekeeper for the output signal of every single neuron. It determines whether a neuron should fire a strong signal forward or remain completely silent. Without these specialized functions, a neural network would behave like a simple, weak linear equation. Linear systems are completely incapable of learning complex real-world relationships like human language or facial features.
In addition to introducing non-linear capabilities, activation functions normalize the erratic mathematical values inside the network. They compress massive numerical sums into a tidy, standardized range, such as between zero and one. One of the most popular activation functions used by modern software developers is the Rectified Linear Unit. This function passes positive numbers through unchanged while instantly converting all negative values into a clean zero.
What’s interesting is how this simple filtering process boosts overall computing efficiency inside massive networks. By turning negative values into zero, it effectively deactivates unnecessary neurons during specific processing tasks. This selective activation saves vast amounts of processing power and accelerates the speed of complex calculations. Choosing the right activation function is paramount for building a fast, accurate machine learning model.
Training the Network: The Learning Process
A newly constructed neural network is completely useless because its internal weights and biases are randomized. It initially makes wild, wildly inaccurate guesses when you feed it fresh data for the first time. Training a network is the rigorous process of adjusting these internal values to maximize predictive accuracy. This fascinating learning cycle utilizes two core repetitive phases known as forward propagation and backpropagation.
During the forward propagation phase, data flows smoothly from the input layer toward the output layer. The network performs all its internal mathematical calculations and delivers a final guess based on its current settings. Next, a specialized mathematical formula called a loss function measures exactly how incorrect that guess was. The loss function outputs a numerical score that represents the total error margin of the system.
Furthermore, the network uses the backpropagation phase to actively learn from its embarrassing mistakes. The system calculates how much each individual weight and bias contributed to the final incorrect prediction. It then sends this error information backward through the layers to adjust the settings accordingly. This continuous loop of guessing, failing, and adjusting repeats millions of times until the error margin disappears.
Real-World Applications of Neural Networks
Neural networks have silently integrated into the fabric of our everyday professional and personal lives. They power the sophisticated digital assistants on your smartphone that understand your spoken voice commands effortlessly. They also analyze global financial markets in real-time to detect fraudulent credit card transactions before they cause damage. Let us explore a few major industries experiencing massive breakthroughs thanks to this fluid technology.
- Computer vision allows autonomous self-driving cars to navigate complex city streets safely by identifying pedestrians and traffic signs instantly.
- Natural language processing models generate highly coherent human-sounding text and translate languages fluidly during international business meetings.
- Healthcare systems utilize deep diagnostic networks to spot microscopic cancerous cells in medical images long before human doctors notice them.
- E-commerce platforms analyze your unique browsing habits to recommend products you are highly likely to purchase in the future.
Summary of Neural Network Essentials
Neural networks represent a spectacular paradigm shift in how humanity develops intelligent computer software systems. By mimicking the elegant structure of the biological brain, they unlock unprecedented pattern recognition capabilities. Information flows through input, hidden, and output layers while individual neurons calculate data using customizable weights and biases. Activation functions introduce vital non-linear capabilities that allow these systems to solve complex real-world mysteries.
Ultimately, the relentless loop of forward propagation and backpropagation enables these digital minds to learn from historical mistakes. This autonomous learning capability powers the modern innovations we enjoy daily, from medical breakthroughs to autonomous vehicles. As computing power continues to accelerate globally, these networks will grow increasingly sophisticated and capable. Embracing this magnificent technology today prepares you to thrive in an artificial intelligence-driven future.
You may also like
-
AI Innovations in Urban Mobility: Shaping the Future of Smart Cities
-
AI Innovations in Sustainable Development: Building a Greener Future with Smart Technology
-
AI Innovations in Creative Industries: How Machines Are Redefining Art and Design
-
AI Innovations in Healthcare: Revolutionizing Diagnosis and Treatment
-
Beyond Algorithms: The Unseen Ethical Layers of AI Innovations